tomoe をつかって文字をさがす
読み不詳の「𠁣」などは、
五筆や鄭碼などの部首検索入力方法から字を探すのが最も手早いはずだが、
これらの入力方法は確定キーをふくめて5ストロークの制限があるために、
複雑な漢字になるとキーの定義がそれほど直観的でないうらみがある。
たとえば鄭碼で「漢」は vebo 、
「嘆」は jebo 、
「𦟫」は qebo 、
そして「暵」は kebo だが、
「𤳉」は kiebo ではなく kibo と記憶しなければならない。
「彘」の字は zmrrmarr でも zmrr でも zmrmでもなく、zmmr と入力しなければならない。
「𠃛」の字が hivv というのも、それほどわかりやすいとは言えない。
つまりこれはおぼえなければ字が出てこない。
中国語を専門にしている人でなければ、部首のキーをおぼえる労力には厭わしいものがある。
だからやはり、普段は慣れた SKK などの方法をつかい、 見知らぬ漢字に出くわした時にのみ、 コードをしらべて入力するという手段は捨てられない。 しかるに「𠁣」の文字があらかじめテキストファイルのデータとして与えられていれば、 文字コードはメモリ上にあるのだから何の苦労もないが、 デジタル化されていない形象から該当する文字コードをさがすのは、 Unicode のコードの記された漢和辞典などを調べる手間がかかる。
それなら手書認識ソフトをつかって、検索の労力を減らすことができないか。
しかし需要のないところに商売は成りたたないとすれば、 市販の手書認識ソフトに明代の白話小説ぐらいでしかお目にかからぬ「𠁣」などという文字の取扱があるのだろうか。
ともあれ uim に組込み可能な tomoe というオープンソースの手書認識ソフト *1 は、 文字パターンの辞書の文法が単純かつ直観的なので、 「𠁣」のような変梃な字を登録するなどの拡張がしやすい。 また SKK 辞書のような JIS の縛りが無いので、 「閒」であろうが、「𪫧」であろうが、Unicode に登録されている文字であれば、 やりたい放題である。
拡張をするまえに、ロケールの制限のかかった日中別の二つの出来合いの辞書を合体させて、使い勝手をよくしておきたい。
デフォルトでは /usr/local/share/tomoe/recognizer に handwriting-ja.xml と handwriting-zh_CN.xml がある。
合体させるには、たとえば
このスクリプト
を用意しておいて、
./mergexmldic.sh uniq handwriting-ja.xml handwriting-zh_CN.xml
とやって、
handwriting-new.xml
という一つの辞書をつくってしまう。
これを handwriting.xml という名前にして元の場所にコピーすれば、
もとの handwriting-ja.xml および handwriting-zh_CN.xml の二つは削除してもよい。
二言語の辞書を合体させたので、
候補の文字が対応フォントのちがいで不ぞろいになるが、
それがみっともなくて厭ならば、
設定ファイル ~/.gtkrc-2.0 の中で gtk-font-name を花園明朝に設定しておけばよい。
しかし uim-tomoe-gtk のために、
他のすべての Gtk-2.0 プログラムに影響するようなコスメティックの改変をするのはよろしくないから、
環境変数 GTK2_RC_FILES で特別の gtkrc-2.0 ファイルを指定するか、
あるいはいっそのこと tomoe-gtk のソースコードに
--- tomoe-gtk-svn/src/tomoe-char-table.c.orig
+++ tomoe-gtk-svn/src/tomoe-char-table.c
@@ -30,6 +30,7 @@
#define DEFAULT_FONT_SCALE 2
/*#define DEFAULT_FONT_SCALE PANGO_SCALE_XX_LARGE*/
+#define TOMOE_FONT_FAMILY "HanaMinA, HanaMinB"
enum {
SELECTED_SIGNAL,
@@ -190,6 +191,7 @@
font_desc = pango_font_description_copy (widget->style->font_desc);
size = pango_font_description_get_size(font_desc);
pango_font_description_set_size(font_desc, size * DEFAULT_FONT_SCALE);
+ pango_font_description_set_family(font_desc, TOMOE_FONT_FAMILY);
gtk_widget_modify_font (widget, font_desc);
pango_font_description_free (font_desc);
}
と書きくわえておいて、ビルドしなおす。
これだけで認識可能な漢字の数が増えるから、 たとえば (残酷物語ですまないが) 十八史略でならう「命じて人彘と曰ふ」の「彘」の字が引けることになる。
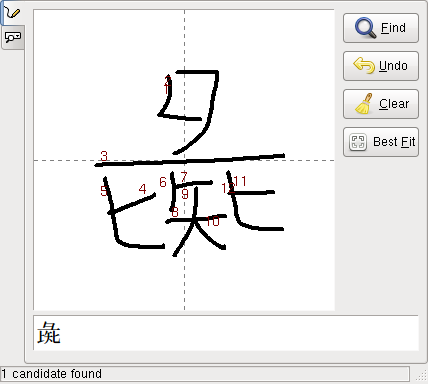
辞書ファイル
handwriting-ja.xml
などを見ればわかるが、
左上を原点として右下にむかって縦横1000ポイントずつの平面上、
筆順に点の座標を記述するだけのシンプルな文法なので、
「𠁣」のような単純なパターンならばテキストエディタをつかってゼロから、
<character>
<utf8>𠁣</utf8>
<strokes>
<stroke>
<point x="310" y="113"/>
<point x="310" y="893"/>
</stroke>
<stroke>
<point x="310" y="113"/>
<point x="753" y="113"/>
<point x="753" y="493"/>
</stroke>
<stroke>
<point x="310" y="243"/>
<point x="753" y="243"/>
</stroke>
<stroke>
<point x="310" y="493"/>
<point x="753" y="493"/>
</stroke>
</strokes>
</character>
のように書くこともできるし、
複雑な文字でも既製の座標記述を切り貼りすれば拡張は容易である。
stroke-editor のようなグラフィカルなプログラムを使えばもっと楽である。
さしあたり
「閒、鷗、𠁣、𠃛、𪫧」
などの文字のパターンを tomoe-dic-suppl.txt に書いておいた。
これをまた上のように
./mergexmldic dupl handwriting.xml tomoe-dic-suppl.txt
とやれば
handwriting-new.xml
ができるので、
handwriting.xml
という名前にして元の場所にコピーすればよい。
で、たとえば「閒」の字を小ぎたなく書いてみて、
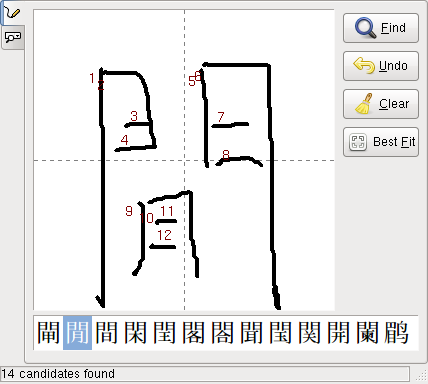
のように候補を表示させ、「閒」をクリックすると、
Gtk の文字列選択バッファにこの文字が入るようだから、
Gtk アプリケーションのアクティブな入力プロンプトにこの字が出現しているはずである。
他に Gtk のアプリケーションが無くとも、
uim-tomoe-gtk
の Search with reading
のタブを開けば、
そこに Reading:
の入力窓があるので、
そこにカーソルを置いてから、
手書認識のタブに戻って該当する文字をクリックすれば、
カーソル上に文字が入力される。
あとはX上の任意の入力場所に「コピペ」すればよい。
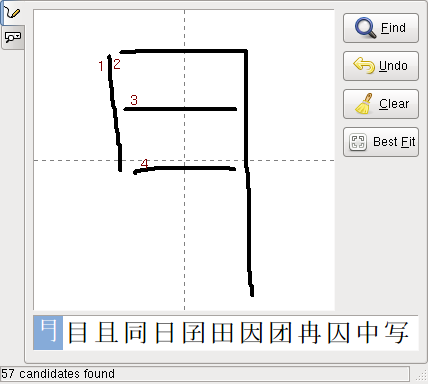
ところで「𪫧」や「𠃛」などの non-BMP の字の候補を uim-tomoe-gtk で表示させると、 文字の配置が少し上にズレてしまうことに気付いた。 これは花園明朝Bフォントの仕様なのかどうか、原因は今のところ不明。