「𠁣」の文字をどのようにキーボード入力するか
「𠁣」と「𠃛」の文字は、 権威ある中国の漢語辞典でも読みがわからないのだから、 拼音や読みがなを用いた漢字入力ができない。 そこでコード入力ということになる。
たとえば GNU Emacs 24 で「𠁣」の文字の上にカーソルを置いて
C-u C-x =
あるいは
C-u M-x what-cursor-position
とやると
(...)
character: 𠁣 (displayed as 𠁣) (codepoint 131171, #o400143, #x20063)
preferred charset: unicode (Unicode (ISO10646))
code point in charset: 0x20063
script: han
syntax: w which means: word
category: .:Base, C:2-byte han, L:Left-to-right (strong), c:Chinese, |:line breakable
to input: type "C-x 8 RET HEX-CODEPOINT" or "C-x 8 RET NAME"
buffer code: #xF0 #xA0 #x81 #xA3
file code: #xF0 #xA0 #x81 #xA3 (encoded by coding system utf-8-unix)
display: by this font (glyph code)
xft:-unknown-HanaMinB-normal-normal-normal-*-14-*-*-*-d-0-iso10646-1 (#xCB)
Character code properties: customize what to show
name: CJK IDEOGRAPH-20063
general-category: Lo (Letter, Other)
decomposition: (131171) ('𠁣')
(...)
うんぬんと出る。
したがって Emacs 上で「𠁣」を入力したければ、
C-x 8 RET 20063 あるいは
M-x insert-char とやって文字コード 20063 を書けばよい。

「𠁣」は Unicode の U+20063 にあり、「𠃛」は U+200db にあり、花園明朝Bフォント があれば表示できる。
X 上の Emacs で表示させるには
~/.emacs などに
(set-fontset-font
"fontset-default"
'unicode-sip
'("HanaMinB" . "iso10646-1"))
と書いておけばよい。
自分が持っているどのフォントが U+20063 のグリフを表示できるかを調べるには、
FreeType と fontconfig のある条件下で
#include <stdio.h>
#include <stdlib.h>
#include <ft2build.h>
#include FT_FREETYPE_H
int main(int argc, char *argv[]) {
FT_Library library;
FT_Face face;
FT_Error error;
FT_UInt present;
char *c = " ";
FT_ULong i = (FT_ULong) strtoul(argv[1], &c, 0);
error = FT_Init_FreeType(&library);
if(error) { printf("Init failure\n"); return 1; }
error = FT_New_Face(library, argv[2], 0, &face);
if(error) return 2;
error = FT_Select_Charmap(face, FT_ENCODING_UNICODE);
if(error) return 3;
present = FT_Get_Char_Index(face, i);
if(present != 0) {
printf("%s has: U+%X (%i)\n", argv[2], (unsigned int) i, present);
}
return 0;
}
というコードを書いて、たとえば check_glyph.c という名前で保存したらば、
gcc `pkg-config --cflags --libs freetype2` check_glyph.c
のようにしてコンパイルして作った a.out というバイナリをつかって、
for file in `fc-list :fontformat=TrueType | sed 's/: .*$//'`
do
a.out 0x20063 $file
done
などとやればよい。
これは
:fontformat=TrueType
などと指定して TrueType フォントファイルを検索対象にしているが、
Noto Sans CJK などの CFF 形式のファイルを検索するには、
:fontformat=CFF を指定する。
Unicode.org
の Unihan Database によると、ふたつとも康熙字典に載っていない字らしい。
uim によるコード入力
Emacs 上での入力に問題は無いが、 X 上でうごくアプリケイションに漢字を入力をするときにはどうすればよいか。
uim では m17n-lib に附属の unicode.mim というモジュールをつかって unicode のコード入力ができるが、
このモジュールは4桁の16進数すなわち BMP までしか対応していないので、
U+200db のような5桁の16進数コードの文字は入力できない。
単純な弥縫策としては、
m17n-db に含まれる unicode.mim に
--- m17n/unicode.mim
+++ m17n/unicode5.mim
@@ -1,4 +1,4 @@
-;; unicode.mim -- Input method for Unicode characters by typing character code
+;; unicode5.mim -- Input method for Unicode characters by typing character code
;; Copyright (C) 2003, 2004, 2005, 2006, 2008, 2009
;; National Institute of Advanced Industrial Science and Technology (AIST)
;; Registration Number H15PRO112
@@ -21,22 +21,22 @@
;; Software Foundation, Inc., 51 Franklin Street, Fifth Floor,
;; Boston, MA 02110-1301, USA.
-(input-method t unicode)
+(input-method t unicode5)
-(description (_"Input method for Unicode BMP characters using hexadigits.
-Type C-u followed by four hexadecimal numbers [0-9A-Fa-f]
+(description (_"Input method for Unicode non-BMP characters using hexadigits.
+Type C-u followed by five hexadecimal numbers [0-9A-Fa-f]
of a Unicode character code.
"))
-(title "UNICODE")
+(title "UNICODE5")
(variable
(prompt (_"Preedit prompt
Prompt string shown in the preedit area while typing hexadecimal numbers.")
"U+"))
(command
- (start (_"Start Unicode
-Start typing hexadecimal numbers of Unicode character.")
+ (start (_"Start Unicode5
+Start typing hexadecimal numbers of Unicode non-BMP character.")
(C-U)))
(map
@@ -62,7 +62,7 @@
(1 (sub this 55)))
(set code (+ (* code 16) this))
(set count (+ count 1))
- (cond ((= count 4)
+ (cond ((= count 5)
(delete @<) (insert code) (shift init))))
(backspace (undo))))
のような修正をくわえた unicode5.mim というファイルをつくっておいて、
uim をビルドしなおせば、
m17n-unicode5
という5桁のコード入力用の入力方法が利用できるようになる。
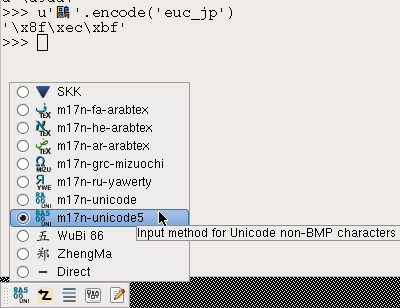
4桁のコードならば従来の m17n-unicode を使えばよい。
uim-skk の辞書に登録
いちいちコード入力する手間をはぶくために、 適当な符牒を決めておいて、 SKK の変換辞書に登録しようと考えても駄目である。 というのもデフォルトの SKK の辞書は EUC-JP とその拡張(EUC-JIS-2004等)にもとづいた文字コードを前提にしているから、 たとえば「鷗」の字は辞書登録できても、 「𠃛」の字は不可能である。
このことは手っ取り早くたとえば python をつかって、
>>> u'鷗'
u'\u9dd7'
>>> u'鷗'.encode('euc_jp')
'\x8f\xec\xbf'
>>> u'𠃛'
u'\U000200db'
>>> u'𠃛'.encode('euc_jp')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UnicodeEncodeError: 'euc_jp' codec can't encode character u'\ud840' in position 0: illegal multibyte sequence
>>> u'閒'
u'\u9592'
>>> u'閒'.encode('euc_jp')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UnicodeEncodeError: 'euc_jp' codec can't encode character u'\u9592' in position 0: illegal multibyte sequence
>>> u'𪫧'
u'\U0002aae7'
>>> u'𪫧'.encode('euc_jp')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UnicodeEncodeError: 'euc_jp' codec can't encode character u'\ud86a' in position 0: illegal multibyte sequence
のようにして調べることができる。
すなわち SKK 辞書には、
仁賢紀にみえる「
もちろん「ひゃっけん」の読みで「百閒」、
また「はや」の読みで「𪫧怜」のような、
タグまじりの文字列で登録するぶんには何の問題もない。
そうすると uim-skk の辞書には /(concat "百閒\073")/ のような形で登録される。
これが嫌ならば uim-skk の辞書を UTF-8 化してしまえばよい。 以下は乱暴だが、てっとりばやく uim-skk を UTF-8 コードに変換する方法:
まず、
uim 1.8.6 の *.scm がインストールされている場所が
/usr/local/share/uim であるとすると、
uim-skk-1.8.6-utf8.patch.gz
を用意しておき、
cd /usr/local/share/uim for f in japanese-act.scm japanese-azik.scm japanese-custom.scm japanese-kzik.scm japanese.scm skk.scm skk-custom.scm do new=`echo $f | sed 's/\.scm$/-utf8.scm/'` iconv -f EUC-JP -t UTF-8 < $f > $new done zcat uim-skk-1.8.6-utf8.patch.gz | patch -p0 -b mv skk.scm skk.scm.orig && mv skk-utf8.scm skk.scm mv skk-custom.scm skk-custom.scm.orig && mv skk-custom-utf8.scm skk-custom.scm rm japanese-custom-utf8.scm.orig japanese-utf8.scm.orig skk-utf8.scm.orig
とやって必要な uim ライブラリの文字コードを UTF-8 に変更しておく。
同じことするのに uim の svn 版からコンパイルする場合は、
このパッチ (uim-svn.patch.gz) と
不足分のアイコンとを用意し、
Google Code
から
sigscheme-0.8.5.tar.bz2
を入手しておいて、
svn co https://github.com/uim/uim/trunk uim-svn cd uim-svn tar xf ../uim-svn-pixmaps-suppl.tar.gz tar xf ../sigscheme-0.8.5.tar.bz2 mv sigscheme-0.8.5 sigscheme zcat ../uim-svn.patch.gz | patch -p1 -b ./autogen.sh ./configure --without-mana --without-prime --with-skk --disable-emacs make su make install GTK_PATH=/usr/lib/gtk-3.0:/usr/local/lib/gtk-3.0 gtk-query-immodules-3.0 > /usr/lib/gtk-3.0/3.0.0/immodules.cache GTK_PATH=/usr/lib/gtk-2.0:/usr/local/lib/gtk-2.0 gtk-query-immodules-2.0 > /usr/lib/gtk-2.0/2.10.0/immodules.cache
などとやってインストールすればよい。
次に SKK-JISYO.L や SKK-JISYO.S やユーザ辞書をすべて、
上記の iconv コマンドを使うなどして UTF-8 のコードに変換しておく。
Emacs の DDSKK でもシステムの SKK-JISYO.L を使用している場合には、
DDSKK の設定ファイルに
(setq skk-jisyo-code 'utf-8)
と書いておいて、こちらも UTF-8 にしてしまったほうがよい。 またSKK辞書サーバを動かしている場合には、サーバ辞書も変換しておく。
あとは UTF-8 形式の個人辞書に
おうがいぜんしゅう /鷗外全集/ ろうかんぶんしゅう /瑯嬛文集/ うちだひゃっけん /内田百閒/ びしばし /𠁣𠃛/
などと身勝手な文字を登録すればよい。
いずれにしても「𠁣」の字の場合は、俗にいう
「
鄭碼および五筆インプットメソッド
ちなみに uim には部首の組み合わせによって5ストローク以内で入力する鄭碼輸入法 (ZhengMa input method) が含まれている。
たとえばこれで「閒」の字を書くには、
「門」が xd で、「月」が q だから、
xdq とするのである。
また「海鷗」を書くには、
v(氵)、
ma(𠂉)、
zy(毌) を組合せた vmzy で「海」が、
h(匚)、
j(口)、
rz(鳥) を組合せた hjjr で「鷗」が出る。
それで「𠁣」は
i(丨) と xb(彐) を組みあわせた ixb によって、
また「𠃛」は
h(匚はEを含む) と
i(丨) とで完結するので、
終端マーカの vv を付した hivv で入力することになっている。
部首と主要な文字のキーを記憶してしまえば、これは相当高速な入力方法であろう。
また uim にはこれと似たような 五筆字型輸入法 (WuBi 86) も用意されていて、
こちらは
「𠁣」が vhk で、
「𠃛」が gnnv で入力できるらしい。